
Linux进程
[TOC]
进程是执行中一段程序,即一旦程序被载入到内存中并准备执行,它就是一个进程。进程是表示资源分配的的基本概念,又是调度运行的基本单位,是系统中的并发执行的单位。
线程:单个进程中执行中每个任务就是一个线程。线程是进程中执行运算的最小单位。
换句话说,进程线程都是对CPU工作时间段的描述(通过task_struct)。
而在Linux系统运行中,程序对应的进程是怎么被创建,被管理,被切换,被调度的呢?
进程的组成,创建,状态机
进程的组成,创建
所有进程都会有一个共同的父进程,PID为1的init(systemd)进程,它是内核引导后启动的第一个进程,主要用来执行一些开机初始化脚本和监视进程,读取配置文件/etc/inittab,永远不会停止。必要的时候可以作为参照。如果某个进程突然成为游离进程(其父进程终止了),此时,这个进程会将init进程作为参照,作为它们的父进程,然后gg。
父进程死了它的子进程也会死。可以通过pstree查看系统内正在运行的各个进程的之间的继承关系。
inittab 是一个不可执行的文本文件,每行的基本格式为:id:runlevels:action:process
- id: 1-2个字符,配置行的唯一标识,不能重复。
- runlevels: 配置行适用的运行级别,可以填入多个运行级别,如12345或者35。
- 0: 关机
- 1: 单用户字符界面
- 2: 不具备网络文件系统(NFS)功能的多用户文字界面
- 3: 具备网络功能的多用户字符界面
- 4: 保留
- 5: 具有网络功能的图形用户界面
- 6: 重新启动系统
- action: 表示init的行为,行为表略。
- process: 为init执行的进程,这些进程都保存在/etc/rcX.d/中,其中X代表运行级别,rc程序接受参数X,然后执行/etc/rcX.d/下面的程序。
- 这些程序其实都是符号链接,以S打头的表示启动该程序,而以K打头的标识终止该程序,后面的数字标识执行顺序,越小越先执行,剩下的标识程序名。
- 系统启动或者切换到该运行级别时会执行以S打头的程序,系统切换到其他运行级别是会终止以K打头的程序。
- 可以通过chkconfig程序进行管理
init程序也是一个进程,和普通进程拥有一样的属性,比如修改了/etc/inittab,想要立即生效,可以通过运行kill -SIGHUP 1来实现,也可以通过init q来实现。
kill命令的工作原理是:向Linux系统的内核发送一个系统操作信号和某个程序的进程标识号,然后系统内核就可以对进程标识号指定的进程进行操作。
在Linux内核中,进程通过一个双向链表来进行管理,每一个进程包含一个进程描述符(task_struct)
进程描述符
- 当把一个程序加载到内存当中,此时,这个时候就有了进程,关于进程,有一个相关的叫做进程控制块(PCB),这个是系统为了方便进行管理进程所设置的一个数据结构,通过PCB,就可以记录进程的特征以及一些信息。 内核当中使用进程描述符task_struct。 这个task_struct就是一个定义的一个结构体,通过这个结构体,可以对进程的所有的相关的信息进行维护,对进程进行管理。
- 推荐一篇文章
进程的组成
- 程序读取的上下文,表示程序读取执行的状态
- 程序当前执行的目录
- 程序服务的文件与目录
- 程序访问的权限
- 内存和其他分配给进程的系统资源
进程的创建
进程总是通过fork系列的系统调用来创建的,最终都是调用do_fork函数,只是参数上的不同而已
fork(do_fork(CLONE_SIGCHLD, …))
- fork创建一个进程时,子进程只是完全复制父进程的资源,复制出来的子进程有自己的task_struct结构和pid,但却复制父进程其它资源(用户空间、文件描述符集)。
- 采用cow(copy on write)写时复制来降低系统调用的开销。
- 一次返回两个值,对于父进程,是子程序的pid,而对于子程序,成功状态下是0。
- 在fork之后,子进程会获得父进程的数据段,堆栈段的副本,而代码段则是共享的。
clone(do_fork(CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGCHLD, …))
- fork()是全部复制,vfork()是共享内存,而clone()是则可以将父进程资源有选择地复制给子进程,前两者都是不带参数的,后者有参数clone_flags。
vfork(do_fork(CLONE_VFORK|CLONE_VM|CLONE_SIGCHLD, …))
vfork系统调用不同于fork,用vfork创建的子进程与父进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,如果这时子进程修改了某个变量,这将影响到父进程。
vfork也是在父进程中返回子进程的进程号,在子进程中返回0。
用 vfork创建子进程后,父进程会被阻塞直到子进程调用exec(exec,将一个新的可执行文件载入到地址空间并执行之)或exit。
vfork的好处是在子进程被创建后往往仅仅是为了调用exec执行另一个程序,因为它就不会对父进程的地址空间有任何引用,所以对地址空间的复制是多余的 ,因此通过vfork共享内存可以减少不必要的开销。
三者的区别
- 拷贝内容
- 访问次序控制
- fork不对父子进程的执行次序进行任何限制,运行顺序由内核的调度算法决定。
- vfork调用后,子进程先运行,父进程挂起,直到子进程调用了exec或者exit后,父子进程的执行次序才不再有限制。
- clone中有标志CLONE_VFORK来决定子进程在运行是父进程是阻塞的还是运行的,如果没有设置,则同时进行,设置了,与fork一样。
CLONE_VM标识:表示共享地址空间(变量等)
CLONE_FILES标志:表示共享文件描述符表
CLONE_VFORK标识:标识父进程会被阻塞,子进程会把父进程的地址空间锁住,直到子进程退出或执行exec时才释放该锁
SIGCHLD标识:共享信号
内核也可以通过kernel_thread函数来创建内核进程
Linux 进程状态机
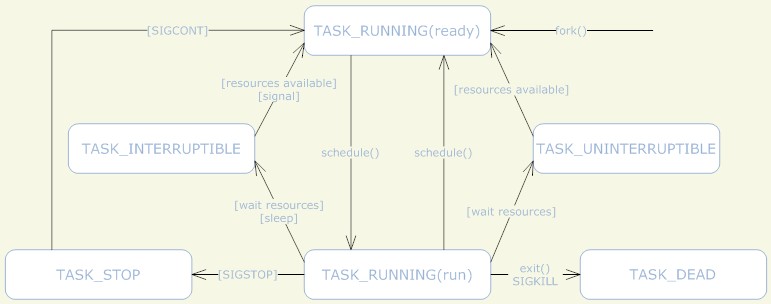
- 虽然进程的状态有好多种,但是进程状态的变迁只有两个方向,从TASK_RUNNING到非TASK_RUNNING,或者相反。总之,进程状态的转换必然会经过TASK_RUNNING,不可能在两个非RUN状态直接转换。
- 进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
- 进程从TASK_RUNNING状态变为非TASK_RUNNING状态,有两种途径。
- 响应信号而进入TASK_STOPED状态,或者TASK_DEAD状态
- 执行程序主动进入TASK_INTERRUPTIBLE状态(如nanosleep调用),或者是TASK_DEAD状态(如exit系统调用),另一方面,也有可能是由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
- 可以通过ps命令来查看系统中存在的进程,以及它们的状态。
- 系统中绝大部分进程都处于TASK_INTERRUPTIBLE状态,因为CPU也就那么几个,所以绝大部分进程都处于睡眠状态。
- TASK_UNINTERRUPTIBLE,不可中断的睡眠状态,指该进程不接受异步信号,如kill -9无法杀死该类进程,这种状态的意义在于,内核中的某些处理流程是不能被打断的,如果响应了异步信号,程序的执行流程中就会给插入了一段处理异步信号的流程(可能只存在于内核态,也可能会延伸到用户态)于是乎,原有的流程就给中断了。 而且,一般系统进程中存在于这个状态的进程是非常少,而且正常来说,都是非常短暂的,基本无法察觉得到的。其实通过vfork调用后,父进程就是处于一种TASK_UNINTERRUPTIBLE的状态,知道子进程调用exec或者exit。
- TASK_STOPPED 或者 TASK_TRACED,暂停状态或跟踪状态。
- 向某个进程发送SIGSTOP信号或者SIGCONT信号可以进入TASK_STOPPED或者恢复到TASK_RUNNING。
- TASK_TRACED状态一般只发生在该进程被调试暂停的时候,该进程停下来,等待跟踪它的进程对其进行操作,TASK_TRACED状态下的进程不响应SIGCONT信号,只能是调试它的进程来恢复它,或者调试进程退出时也会恢复。
- TASK_DEAD - EXIT_ZOMBIE,退出状态,进程成为僵尸进程。
- 进程在退出的过程中,处于TASK_DEAD状态,在退出过程中,进程所占有的资源将会被回收,除了task_struct结构(以及少数资源),也就是说,进程表只存在这个进程对应的task_struct这个空壳,所以叫做僵尸,由父进程负责收集,收尸。从这个尸体(task_struct)中可以得到很多有用的信息,如子进程的退出码,一些统计信息(虽然内核也可以吧这些信息保存在其他的地方,但是不这么做)。父进程可以通过wait系列的系统调用来等待子进程的退出,然后获取退出信息,然后wait系列的系统调用会清理尸体(task_struct)。
- 子进程在退出的时候,内核会给父进程发送一个信号(SIGCHLD)来通知父进程过来收尸。
- 进程可以通过调用exit来进入该状态。
- TASK_DEAD - EXIT_DEAD,退出状态,进程即将给销毁。
- 进程也有可能不会经历TASK_DEAD - EXIT_ZOMBIE状态而直接销毁。如detach过的进程,SIGCHLD信号的handle为SIG_IGN,忽略了SIGCHLD信号。
进程的调度
无论是在批处理系统还是分时系统中,用户进程数一般都多于处理机数、这将导致它们互相争夺处理机。另外,系统进程也同样需要使用处理机。这就要求进程调度程序按一定的策略,动态地把处理机分配给处于就绪队列中的某一个进程,以使之执行。这就是进程调度。
当cpu中正在执行的进程(process A)被移出(suspend),cpu中当前进程的相关信息写到需要移除的进程的进程描述符(task_strut)中,下一个进程(process B)被内核读取(该过程称为resume,恢复)到cpu中, 注意:进程的切换也是必须由内核来执行的。进程的切换就是通过用户空间和内核模式的不断切换来完成的。进程切换=CPU加载上下文+CPU执行+CPU保存上下文
Linux 进程调度的目标
- 高效性: 高效性意味着在相同时间下要完成更多的任务。调度程序会被频繁的执行,所以调度程序要尽可能的高效。
- 加强交互性能: 在系统相当的负载下,也要保证系统的响应时间。
- 保证公平和避免饥渴
- SMP调度: 调度程序必须支持多处理系统。
- 软实时调度: 系统必须有效的调用实时进程,但不保证一定满足其要求。
Linux 进程优先级
任何时候,实时进程的优先级都高于普通进程,实时进程只会被更高级的实时进程抢占
Linux 进程调度
实时进程调度
实时进程,只有静态优先级,因为内核不会根据休眠等因素对其静态优先级做调整,范围是在0 - MAX_RT_PRIO - 1 之间。而nice值,影响的优先级在MAX_RT_PRIO - MAX_RT_PRIO + 40之间的进程。
MAX_RT_PRIO: 默认配置为100.
不同于普通进程,实时进程高的进程总是先于优先级低的进程执行,直到实时优先级高的实时进程无法执行,实时进程总是被认为处于活动状态。
如果有数个进程相同的实时进程,那么系统会按照进程在队列上的顺序选择进程。
例如CPU运行实时进程A的实时优先级为a,而此时有一个实时优先级为b的实时进程B进入可运行状态,那么只要b > a,系统将会中断A的执行,而优先执行B,直到B无法执行。
调度策略
- FIFO 的进程,意味着只有当前进程执行完毕才会轮到其他进程执行。
- RR 的进程,内核会为进程分配时间片,一旦时间片消耗完毕,内核会将该进程置于进程队列的末尾,然后运行其他相同优先级别的进程,如果没有其他相同优先级的进程,则该进程会继续执行。
对于实时进程,高优先级别的进程执行到无法执行了,才会轮到低优先级别的进程执行。
非实时进程调度
Linux 对于普通进程,根据动态优先级进行调整,而动态优先级是由静态优先级(static_prio)调整而来的。 静态优先级是用户不可见的,隐藏在内核中,而内核会给用户一个可以影响静态优先级的接口,那就是nice值。
static_prio = MAX_RT_PRIO + nice + 20
nice 值与静态优先级的关系如上所示。nice值的范围是-20 - 19之间,所以静态优先级范围在100 - 139之间。
普通进程的动态优先级越低,优先越高,与实时进程相反,也就是说,nice的值越大,优先级越低。
进程时间片是完全依赖于static_prio 定制的,如下所示
$$
base\ time\ quantum(ms) =
\begin{cases}
(140 - \text{static_prio})\times20, \text{static_prio < 120}\
(140 - \text{static_prio})\times20, \text{static_prio } \ge \text{ 120}
\end{cases}
$$
进程调度的其他因素
系统在调度进程的时候,还会考虑其他因素,进而来计算出一个叫进程动态优先级的东西,基于这个来实施调度。
进程属性
- 交互式进程(I/O密集型,等待IO,对cpu的需求量小)
- 批处理进程(CPU密集型)
- 实时进程
分配策略
不仅要考虑静态优先级,也要考虑进程的属性,如果进程是属于交互式进程,那么可以适当的调高它的优先级,使得界面反应更加迅速,从而提高用户体验。
交互式进程可以从一个平均睡眠时间来进行判断,如果进程过去睡眠的时间越多,则越有可能属于交互式进程。则系统在调度的时候,会给该进程更多的奖励(bonus),以便该进程有更多的时间能够执行。奖励(bonus)的范围为0 - 10。
睡眠和CPU耗时反应了进程IO密集和CPU密集两大瞬时特点,不同时期,一个进程可能即是CPU密集型也是IO密集型进程。对于表现为IO密集的进程,应该经常运行,但每次时间片不要太长。对于表现为CPU密集的进程,CPU不应该让其经常运行,但每次运行时间片要长。交互进程为例,假如之前其其大部分时间在于等待CPU,这时为了调高相应速度,就需要增加奖励分。另一方面,如果此进程总是耗尽每次分配给它的时间片,为了对其他进程公平,就要增加这个进程的惩罚分数。
系统会严格按照动态优先级高低的顺序安排进程执行。动态优先级高的进程进入运行状态,或者时间片消耗完毕后才会轮到动态优先级低的进程执行。
动态优先级的计算主要考虑两个因素
- 静态优先级(static_prio)
- 平均睡眠时间(bonus)
计算公式如下
$$
\text{dynamic_prio} = max{100,\ min{static_prio- bonus+5,\ 139} }
$$Linux2.6在计算的时候有空间换时间的策略,从而保证最优进程能够在O(1)的时间内完成。
CFS 的virtutime机制。
进程切换 (Context switch)
当cpu中正在执行的进程(process A)被移出(suspend),cpu中当前进程的相关信息写到需要移除的进程的进程描述符(task_strut)中,下一个进程(process B)被内核读取(该过程称为resume,恢复)到cpu中, 注意:进程的切换也是必须由内核来执行的。进程的切换就是通过用户空间和内核模式的不断切换来完成的。进程切换=CPU加载上下文+CPU执行+CPU保存上下文
调度触发的时机
当前进程进入非可执行状态
抢占
- 进程用完了时间片
- 出现优先级更高的进程,会被影响而唤醒。
内核在响应时钟中断的过程中,发现当前进程的时间片已经用完
内核在响应时钟中断的过程中,发现优先级更高的进程所等待的外部资源是可用的,于是唤醒它。
其他相关
内核抢占
- 理想情况下,只要满足了出现优先级更高的进程这个条件,当前进程就应该被立刻抢占。但是就像多线程程序需要使用锁来保护临界区资源一样,内核中也有很多这样的临界区,来保证一些程序不给抢占。或者是处于效率考虑。
- Linux2.4不支持内核抢占,进程在内核态是不允许抢占的,只有返回用户态时会触发调整。
- Linux2.6支持内核抢占,但是很多地方为了保护临界区资源而临时性的禁用抢占。
SMP调度下的负载均衡问题
多处理器下,每个CPU都有对应的可执行队列,但是一个可执行状态的进程同一时刻只能存在于一个可执行队列中。
问题
- 每个CPU可执行队列中进程数目不均衡的时候,要怎么调整,什么时候算作是不均衡,需要调整?
- CPU之间的关系,两个CPU之间,是不是相互独立的,cache可以共享吗?或者,是不是由同一个物理CPU通过超线程技术虚拟出来的
- 反正就是乱七八糟的就是了。。。。。
优先级继承
假如有一个进程A,因为要进入临界区,但是临界区有了B,而在等待睡眠,直到B退出临界区后,进程A才会被唤醒。
可能存在这么一种情况,A的优先级很高,而B的优先级很低,B进入了临界区,但是却给其他优先级高于B低于A的进程C抢占,A就等不到运行,此时叫做优先级反转。此时会通过以下方法解决:在A开始等待的时候,将A的优先级赋给B,直到B退出临界区后恢复其原本的优先级。
这就是优先级继承。
中断处理程序的优化
正常来说,中断处理程序处于一个不可调度的上下文中,CPU响应硬件中断自动跳转到内核设定的中断处理程序去执行,再到处理程序执行完。这整个过程中是不能被抢占的。
一个进程如果被抢占了,可以通过保存在它的进程控制块(task_struct)中的信息,在之后的某个时间恢复它的运行,而中断上下文是没有task_struct的,所以是不可能杯抢占的。
也就是说,中断程序的伪优先级比任何进程要高,但是呢在实际中,某些实时进程会拥有比中断进程更高的优先级。所以在一些系统中,会给中断处理程序赋予task_struct以及优先级。但是会影响一些性能,但是却能保证实时。
调度程序的效率问题
优先级明确了哪个进程应该被调度执行,而调度程序还要关心效率问题,因为会被频繁的执行,所以效率很重要的。
所以,调度程序,如何来获得应该被执行的程序,就是一个问题了。
在Linux2.4,可执行状态的进程会被放在一个链表中,每次调度,扫描整个链表,以找出最优的那个进程来运行,复杂度为O(N)
在Linux2.6早期,可执行状态的进车功能会被挂载N(N=140)个链表中,每一个链表代表一个优先级,系统支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出链表头的进程即可。复杂度为O(1).
而在现在Linux2.6的版本中,可执行状态的进程会按照优先级顺序被挂载一个红黑树上,每次调度,找出树中优先级最高的那个进程。复杂度为O(LogN)
只是为了公平
第一种是基于空间换时间的策略,在一组数目不大的链表中来实现的,这样子优先级的取值范围很小(大了会浪费太多空间),区分度不大不能满足公平性的需求,而使用红黑树对优先级的取值没有限制,区分度可以更高。而且在同等情况下,140个优先级,O(LogN)的复杂度也不会太差。
处理机的三级调度

- 作业调度(高级调度)
- 内存调度(中级调度)
- 进程调度(低级调度)
作业调度从外存的后备队列中选择一批作业进入内存,为它们建立进程,这些进程被送入就绪队列,进程调度从就绪队列中选出一个进程,并把其状态改为运行状态,把CPU分配给它。中级调度是为了提高内存的利用率,系统将那些暂时不能运行的进程挂起来。当内存空间宽松时,通过中级调度选择具备运行条件的进程,将其唤醒。
- 作业调度为进程活动做准备,进程调度使进程正常活动起来,中级调度将暂时不能运行的进程挂起,中级调度处于作业调度和进程调度之间。
- 作业调度次数少,中级调度次数略多,进程调度频率最高。
- 进程调度是最基本的,不可或缺。
推荐一篇文章# Linux进程
[TOC]
进程是执行中一段程序,即一旦程序被载入到内存中并准备执行,它就是一个进程。进程是表示资源分配的的基本概念,又是调度运行的基本单位,是系统中的并发执行的单位。
线程:单个进程中执行中每个任务就是一个线程。线程是进程中执行运算的最小单位。
换句话说,进程线程都是对CPU工作时间段的描述(通过task_struct)。
而在Linux系统运行中,程序对应的进程是怎么被创建,被管理,被切换,被调度的呢?
进程的组成,创建,状态机
进程的组成,创建
所有进程都会有一个共同的父进程,PID为1的init(systemd)进程,它是内核引导后启动的第一个进程,主要用来执行一些开机初始化脚本和监视进程,读取配置文件/etc/inittab,永远不会停止。必要的时候可以作为参照。如果某个进程突然成为游离进程(其父进程终止了),此时,这个进程会将init进程作为参照,作为它们的父进程,然后gg。
父进程死了它的子进程也会死。可以通过pstree查看系统内正在运行的各个进程的之间的继承关系。
inittab 是一个不可执行的文本文件,每行的基本格式为:id:runlevels:action:process
- id: 1-2个字符,配置行的唯一标识,不能重复。
- runlevels: 配置行适用的运行级别,可以填入多个运行级别,如12345或者35。
- 0: 关机
- 1: 单用户字符界面
- 2: 不具备网络文件系统(NFS)功能的多用户文字界面
- 3: 具备网络功能的多用户字符界面
- 4: 保留
- 5: 具有网络功能的图形用户界面
- 6: 重新启动系统
- action: 表示init的行为,行为表略。
- process: 为init执行的进程,这些进程都保存在/etc/rcX.d/中,其中X代表运行级别,rc程序接受参数X,然后执行/etc/rcX.d/下面的程序。
- 这些程序其实都是符号链接,以S打头的表示启动该程序,而以K打头的标识终止该程序,后面的数字标识执行顺序,越小越先执行,剩下的标识程序名。
- 系统启动或者切换到该运行级别时会执行以S打头的程序,系统切换到其他运行级别是会终止以K打头的程序。
- 可以通过chkconfig程序进行管理
init程序也是一个进程,和普通进程拥有一样的属性,比如修改了/etc/inittab,想要立即生效,可以通过运行kill -SIGHUP 1来实现,也可以通过init q来实现。
kill命令的工作原理是:向Linux系统的内核发送一个系统操作信号和某个程序的进程标识号,然后系统内核就可以对进程标识号指定的进程进行操作。
在Linux内核中,进程通过一个双向链表来进行管理,每一个进程包含一个进程描述符(task_struct)
进程描述符
- 当把一个程序加载到内存当中,此时,这个时候就有了进程,关于进程,有一个相关的叫做进程控制块(PCB),这个是系统为了方便进行管理进程所设置的一个数据结构,通过PCB,就可以记录进程的特征以及一些信息。 内核当中使用进程描述符task_struct。 这个task_struct就是一个定义的一个结构体,通过这个结构体,可以对进程的所有的相关的信息进行维护,对进程进行管理。
- 推荐一篇文章
进程的组成
- 程序读取的上下文,表示程序读取执行的状态
- 程序当前执行的目录
- 程序服务的文件与目录
- 程序访问的权限
- 内存和其他分配给进程的系统资源
进程的创建
进程总是通过fork系列的系统调用来创建的,最终都是调用do_fork函数,只是参数上的不同而已
fork(do_fork(CLONE_SIGCHLD, …))
- fork创建一个进程时,子进程只是完全复制父进程的资源,复制出来的子进程有自己的task_struct结构和pid,但却复制父进程其它资源(用户空间、文件描述符集)。
- 采用cow(copy on write)写时复制来降低系统调用的开销。
- 一次返回两个值,对于父进程,是子程序的pid,而对于子程序,成功状态下是0。
- 在fork之后,子进程会获得父进程的数据段,堆栈段的副本,而代码段则是共享的。
clone(do_fork(CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGCHLD, …))
- fork()是全部复制,vfork()是共享内存,而clone()是则可以将父进程资源有选择地复制给子进程,前两者都是不带参数的,后者有参数clone_flags。
vfork(do_fork(CLONE_VFORK|CLONE_VM|CLONE_SIGCHLD, …))
vfork系统调用不同于fork,用vfork创建的子进程与父进程共享地址空间,也就是说子进程完全运行在父进程的地址空间上,如果这时子进程修改了某个变量,这将影响到父进程。
vfork也是在父进程中返回子进程的进程号,在子进程中返回0。
用 vfork创建子进程后,父进程会被阻塞直到子进程调用exec(exec,将一个新的可执行文件载入到地址空间并执行之)或exit。
vfork的好处是在子进程被创建后往往仅仅是为了调用exec执行另一个程序,因为它就不会对父进程的地址空间有任何引用,所以对地址空间的复制是多余的 ,因此通过vfork共享内存可以减少不必要的开销。
三者的区别
- 拷贝内容
- 访问次序控制
- fork不对父子进程的执行次序进行任何限制,运行顺序由内核的调度算法决定。
- vfork调用后,子进程先运行,父进程挂起,直到子进程调用了exec或者exit后,父子进程的执行次序才不再有限制。
- clone中有标志CLONE_VFORK来决定子进程在运行是父进程是阻塞的还是运行的,如果没有设置,则同时进行,设置了,与fork一样。
CLONE_VM标识:表示共享地址空间(变量等)
CLONE_FILES标志:表示共享文件描述符表
CLONE_VFORK标识:标识父进程会被阻塞,子进程会把父进程的地址空间锁住,直到子进程退出或执行exec时才释放该锁
SIGCHLD标识:共享信号
内核也可以通过kernel_thread函数来创建内核进程
Linux 进程状态机
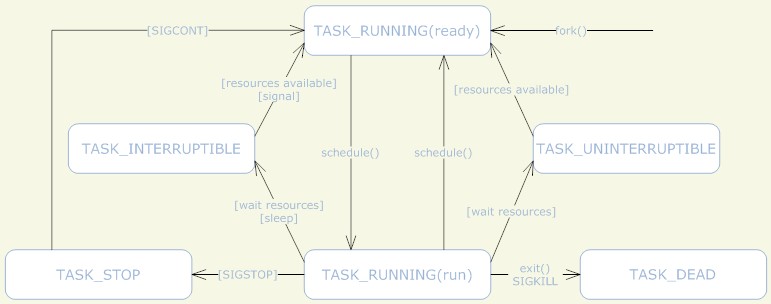
- 虽然进程的状态有好多种,但是进程状态的变迁只有两个方向,从TASK_RUNNING到非TASK_RUNNING,或者相反。总之,进程状态的转换必然会经过TASK_RUNNING,不可能在两个非RUN状态直接转换。
- 进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
- 进程从TASK_RUNNING状态变为非TASK_RUNNING状态,有两种途径。
- 响应信号而进入TASK_STOPED状态,或者TASK_DEAD状态
- 执行程序主动进入TASK_INTERRUPTIBLE状态(如nanosleep调用),或者是TASK_DEAD状态(如exit系统调用),另一方面,也有可能是由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
- 可以通过ps命令来查看系统中存在的进程,以及它们的状态。
- 系统中绝大部分进程都处于TASK_INTERRUPTIBLE状态,因为CPU也就那么几个,所以绝大部分进程都处于睡眠状态。
- TASK_UNINTERRUPTIBLE,不可中断的睡眠状态,指该进程不接受异步信号,如kill -9无法杀死该类进程,这种状态的意义在于,内核中的某些处理流程是不能被打断的,如果响应了异步信号,程序的执行流程中就会给插入了一段处理异步信号的流程(可能只存在于内核态,也可能会延伸到用户态)于是乎,原有的流程就给中断了。 而且,一般系统进程中存在于这个状态的进程是非常少,而且正常来说,都是非常短暂的,基本无法察觉得到的。其实通过vfork调用后,父进程就是处于一种TASK_UNINTERRUPTIBLE的状态,知道子进程调用exec或者exit。
- TASK_STOPPED 或者 TASK_TRACED,暂停状态或跟踪状态。
- 向某个进程发送SIGSTOP信号或者SIGCONT信号可以进入TASK_STOPPED或者恢复到TASK_RUNNING。
- TASK_TRACED状态一般只发生在该进程被调试暂停的时候,该进程停下来,等待跟踪它的进程对其进行操作,TASK_TRACED状态下的进程不响应SIGCONT信号,只能是调试它的进程来恢复它,或者调试进程退出时也会恢复。
- TASK_DEAD - EXIT_ZOMBIE,退出状态,进程成为僵尸进程。
- 进程在退出的过程中,处于TASK_DEAD状态,在退出过程中,进程所占有的资源将会被回收,除了task_struct结构(以及少数资源),也就是说,进程表只存在这个进程对应的task_struct这个空壳,所以叫做僵尸,由父进程负责收集,收尸。从这个尸体(task_struct)中可以得到很多有用的信息,如子进程的退出码,一些统计信息(虽然内核也可以吧这些信息保存在其他的地方,但是不这么做)。父进程可以通过wait系列的系统调用来等待子进程的退出,然后获取退出信息,然后wait系列的系统调用会清理尸体(task_struct)。
- 子进程在退出的时候,内核会给父进程发送一个信号(SIGCHLD)来通知父进程过来收尸。
- 进程可以通过调用exit来进入该状态。
- TASK_DEAD - EXIT_DEAD,退出状态,进程即将给销毁。
- 进程也有可能不会经历TASK_DEAD - EXIT_ZOMBIE状态而直接销毁。如detach过的进程,SIGCHLD信号的handle为SIG_IGN,忽略了SIGCHLD信号。
进程的调度
无论是在批处理系统还是分时系统中,用户进程数一般都多于处理机数、这将导致它们互相争夺处理机。另外,系统进程也同样需要使用处理机。这就要求进程调度程序按一定的策略,动态地把处理机分配给处于就绪队列中的某一个进程,以使之执行。这就是进程调度。
当cpu中正在执行的进程(process A)被移出(suspend),cpu中当前进程的相关信息写到需要移除的进程的进程描述符(task_strut)中,下一个进程(process B)被内核读取(该过程称为resume,恢复)到cpu中, 注意:进程的切换也是必须由内核来执行的。进程的切换就是通过用户空间和内核模式的不断切换来完成的。进程切换=CPU加载上下文+CPU执行+CPU保存上下文
Linux 进程调度的目标
- 高效性: 高效性意味着在相同时间下要完成更多的任务。调度程序会被频繁的执行,所以调度程序要尽可能的高效。
- 加强交互性能: 在系统相当的负载下,也要保证系统的响应时间。
- 保证公平和避免饥渴
- SMP调度: 调度程序必须支持多处理系统。
- 软实时调度: 系统必须有效的调用实时进程,但不保证一定满足其要求。
Linux 进程优先级
任何时候,实时进程的优先级都高于普通进程,实时进程只会被更高级的实时进程抢占
Linux 进程调度
实时进程调度
实时进程,只有静态优先级,因为内核不会根据休眠等因素对其静态优先级做调整,范围是在0 - MAX_RT_PRIO - 1 之间。而nice值,影响的优先级在MAX_RT_PRIO - MAX_RT_PRIO + 40之间的进程。
MAX_RT_PRIO: 默认配置为100.
不同于普通进程,实时进程高的进程总是先于优先级低的进程执行,直到实时优先级高的实时进程无法执行,实时进程总是被认为处于活动状态。
如果有数个进程相同的实时进程,那么系统会按照进程在队列上的顺序选择进程。
例如CPU运行实时进程A的实时优先级为a,而此时有一个实时优先级为b的实时进程B进入可运行状态,那么只要b > a,系统将会中断A的执行,而优先执行B,直到B无法执行。
调度策略
- FIFO 的进程,意味着只有当前进程执行完毕才会轮到其他进程执行。
- RR 的进程,内核会为进程分配时间片,一旦时间片消耗完毕,内核会将该进程置于进程队列的末尾,然后运行其他相同优先级别的进程,如果没有其他相同优先级的进程,则该进程会继续执行。
对于实时进程,高优先级别的进程执行到无法执行了,才会轮到低优先级别的进程执行。
非实时进程调度
Linux 对于普通进程,根据动态优先级进行调整,而动态优先级是由静态优先级(static_prio)调整而来的。 静态优先级是用户不可见的,隐藏在内核中,而内核会给用户一个可以影响静态优先级的接口,那就是nice值。
static_prio = MAX_RT_PRIO + nice + 20
nice 值与静态优先级的关系如上所示。nice值的范围是-20 - 19之间,所以静态优先级范围在100 - 139之间。
普通进程的动态优先级越低,优先越高,与实时进程相反,也就是说,nice的值越大,优先级越低。
进程时间片是完全依赖于static_prio 定制的,如下所示
$$
base\ time\ quantum(ms) =
\begin{cases}
(140 - \text{static_prio})\times20, \text{static_prio < 120}\
(140 - \text{static_prio})\times20, \text{static_prio } \ge \text{ 120}
\end{cases}
$$
进程调度的其他因素
系统在调度进程的时候,还会考虑其他因素,进而来计算出一个叫进程动态优先级的东西,基于这个来实施调度。
进程属性
- 交互式进程(I/O密集型,等待IO,对cpu的需求量小)
- 批处理进程(CPU密集型)
- 实时进程
分配策略
不仅要考虑静态优先级,也要考虑进程的属性,如果进程是属于交互式进程,那么可以适当的调高它的优先级,使得界面反应更加迅速,从而提高用户体验。
交互式进程可以从一个平均睡眠时间来进行判断,如果进程过去睡眠的时间越多,则越有可能属于交互式进程。则系统在调度的时候,会给该进程更多的奖励(bonus),以便该进程有更多的时间能够执行。奖励(bonus)的范围为0 - 10。
睡眠和CPU耗时反应了进程IO密集和CPU密集两大瞬时特点,不同时期,一个进程可能即是CPU密集型也是IO密集型进程。对于表现为IO密集的进程,应该经常运行,但每次时间片不要太长。对于表现为CPU密集的进程,CPU不应该让其经常运行,但每次运行时间片要长。交互进程为例,假如之前其其大部分时间在于等待CPU,这时为了调高相应速度,就需要增加奖励分。另一方面,如果此进程总是耗尽每次分配给它的时间片,为了对其他进程公平,就要增加这个进程的惩罚分数。
系统会严格按照动态优先级高低的顺序安排进程执行。动态优先级高的进程进入运行状态,或者时间片消耗完毕后才会轮到动态优先级低的进程执行。
动态优先级的计算主要考虑两个因素
- 静态优先级(static_prio)
- 平均睡眠时间(bonus)
计算公式如下
$$
\text{dynamic_prio} = max{100,\ min{static_prio- bonus+5,\ 139} }
$$Linux2.6在计算的时候有空间换时间的策略,从而保证最优进程能够在O(1)的时间内完成。
CFS 的virtutime机制。
进程切换 (Context switch)
当cpu中正在执行的进程(process A)被移出(suspend),cpu中当前进程的相关信息写到需要移除的进程的进程描述符(task_strut)中,下一个进程(process B)被内核读取(该过程称为resume,恢复)到cpu中, 注意:进程的切换也是必须由内核来执行的。进程的切换就是通过用户空间和内核模式的不断切换来完成的。进程切换=CPU加载上下文+CPU执行+CPU保存上下文
调度触发的时机
当前进程进入非可执行状态
抢占
- 进程用完了时间片
- 出现优先级更高的进程,会被影响而唤醒。
内核在响应时钟中断的过程中,发现当前进程的时间片已经用完
内核在响应时钟中断的过程中,发现优先级更高的进程所等待的外部资源是可用的,于是唤醒它。
其他相关
内核抢占
- 理想情况下,只要满足了出现优先级更高的进程这个条件,当前进程就应该被立刻抢占。但是就像多线程程序需要使用锁来保护临界区资源一样,内核中也有很多这样的临界区,来保证一些程序不给抢占。或者是处于效率考虑。
- Linux2.4不支持内核抢占,进程在内核态是不允许抢占的,只有返回用户态时会触发调整。
- Linux2.6支持内核抢占,但是很多地方为了保护临界区资源而临时性的禁用抢占。
SMP调度下的负载均衡问题
多处理器下,每个CPU都有对应的可执行队列,但是一个可执行状态的进程同一时刻只能存在于一个可执行队列中。
问题
- 每个CPU可执行队列中进程数目不均衡的时候,要怎么调整,什么时候算作是不均衡,需要调整?
- CPU之间的关系,两个CPU之间,是不是相互独立的,cache可以共享吗?或者,是不是由同一个物理CPU通过超线程技术虚拟出来的
- 反正就是乱七八糟的就是了。。。。。
优先级继承
假如有一个进程A,因为要进入临界区,但是临界区有了B,而在等待睡眠,直到B退出临界区后,进程A才会被唤醒。
可能存在这么一种情况,A的优先级很高,而B的优先级很低,B进入了临界区,但是却给其他优先级高于B低于A的进程C抢占,A就等不到运行,此时叫做优先级反转。此时会通过以下方法解决:在A开始等待的时候,将A的优先级赋给B,直到B退出临界区后恢复其原本的优先级。
这就是优先级继承。
中断处理程序的优化
正常来说,中断处理程序处于一个不可调度的上下文中,CPU响应硬件中断自动跳转到内核设定的中断处理程序去执行,再到处理程序执行完。这整个过程中是不能被抢占的。
一个进程如果被抢占了,可以通过保存在它的进程控制块(task_struct)中的信息,在之后的某个时间恢复它的运行,而中断上下文是没有task_struct的,所以是不可能杯抢占的。
也就是说,中断程序的伪优先级比任何进程要高,但是呢在实际中,某些实时进程会拥有比中断进程更高的优先级。所以在一些系统中,会给中断处理程序赋予task_struct以及优先级。但是会影响一些性能,但是却能保证实时。
调度程序的效率问题
优先级明确了哪个进程应该被调度执行,而调度程序还要关心效率问题,因为会被频繁的执行,所以效率很重要的。
所以,调度程序,如何来获得应该被执行的程序,就是一个问题了。
在Linux2.4,可执行状态的进程会被放在一个链表中,每次调度,扫描整个链表,以找出最优的那个进程来运行,复杂度为O(N)
在Linux2.6早期,可执行状态的进车功能会被挂载N(N=140)个链表中,每一个链表代表一个优先级,系统支持多少个优先级就有多少个链表。每次调度,调度程序只需要从第一个不为空的链表中取出链表头的进程即可。复杂度为O(1).
而在现在Linux2.6的版本中,可执行状态的进程会按照优先级顺序被挂载一个红黑树上,每次调度,找出树中优先级最高的那个进程。复杂度为O(LogN)
只是为了公平
第一种是基于空间换时间的策略,在一组数目不大的链表中来实现的,这样子优先级的取值范围很小(大了会浪费太多空间),区分度不大不能满足公平性的需求,而使用红黑树对优先级的取值没有限制,区分度可以更高。而且在同等情况下,140个优先级,O(LogN)的复杂度也不会太差。
处理机的三级调度
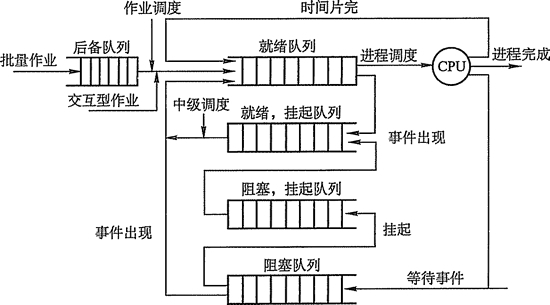
- 作业调度(高级调度)
- 内存调度(中级调度)
- 进程调度(低级调度)
作业调度从外存的后备队列中选择一批作业进入内存,为它们建立进程,这些进程被送入就绪队列,进程调度从就绪队列中选出一个进程,并把其状态改为运行状态,把CPU分配给它。中级调度是为了提高内存的利用率,系统将那些暂时不能运行的进程挂起来。当内存空间宽松时,通过中级调度选择具备运行条件的进程,将其唤醒。
- 作业调度为进程活动做准备,进程调度使进程正常活动起来,中级调度将暂时不能运行的进程挂起,中级调度处于作业调度和进程调度之间。
- 作业调度次数少,中级调度次数略多,进程调度频率最高。
- 进程调度是最基本的,不可或缺。
推荐一篇文章